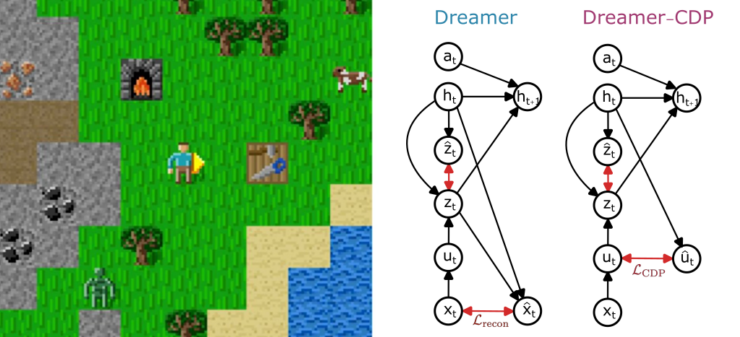
In our new tiny paper accepted at the ICLR workshop on world models we introduce Dreamer-CDP, a Dreamer variant that learns a world model without reconstructing raw pixel observations.
Preprint: https://arxiv.org/abs/2603.07083
Standard model-based reinforcement learning (MBRL) agents like Dreamer learn internal “world models” by predicting what the environment looks like, thus, essentially reconstructing images from memory. While effective, this can cause the agent to focus on visually rich but task-irrelevant details. Reconstruction-free alternatives have been proposed, but until now they have consistently underperformed on challenging benchmarks.
Dreamer-CDP closes this gap by adding a JEPA-style predictor that operates on compact, continuous internal representations rather than raw pixels. Instead of asking “what does the next frame look like?”, the model learns to predict what the next abstract state should be. This simple modification is enough to match the performance of the reconstruction-based Dreamer baseline on the Crafter benchmark, a Minecraft-inspired environment designed to test long-term reasoning and exploration, while outperforming all previous reconstruction-free Dreamer variants.
The results suggest that reconstruction-free world models are a viable path forward, potentially offering computational savings and better generalization in complex, high-dimensional environments.