Fabian’s paper “Understanding Self-Supervised Learning via Latent Distribution Matching” was accepted as ICML spotlight!
https://arxiv.org/abs/2605.03517
We unify self-supervised learning (SSL) algorithms (e.g., contrastive, VICReg, stopgrad) via latent distribution matching (LDM), which matches an induced latent distribution to an explicit latent model.
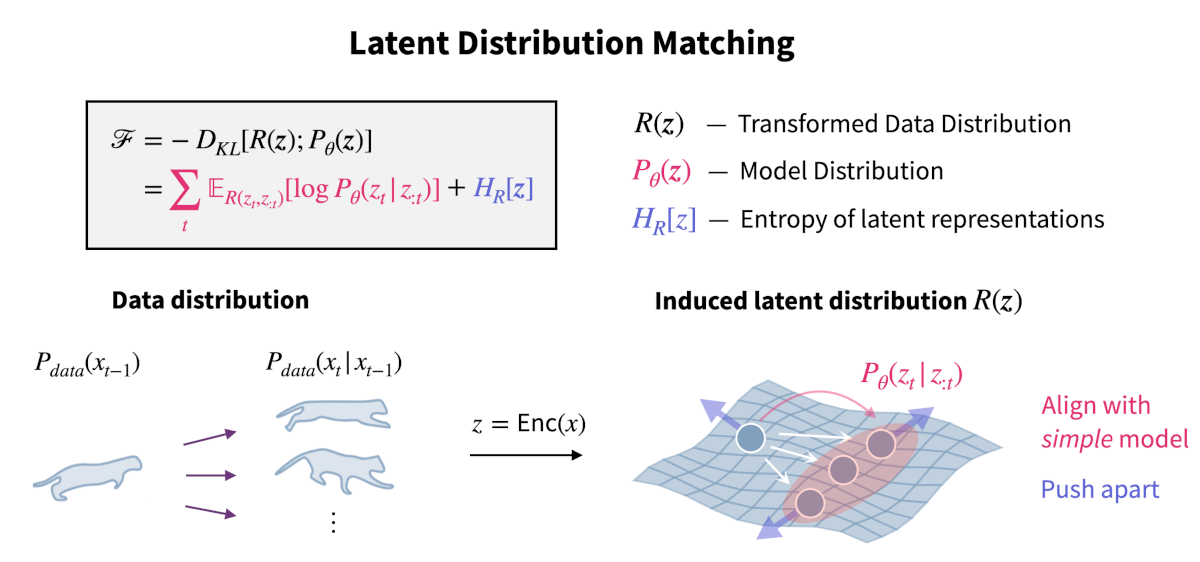
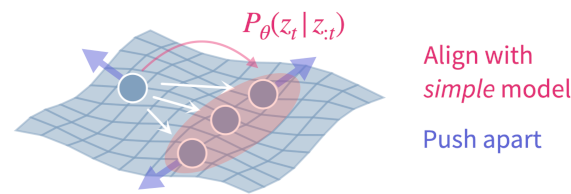
All objectives derived within the LDM framework consist of (i) an alignment term that maximizes log-likelihood under the assumed latent model and (ii) a uniformity term that maximizes entropy of the embeddings to prevent representational collapse.
A flurry of existing SSL methods emerges from LDM as special cases under distinct choices of the latent model and entropy estimators. Specifically, we derive SimCLR, VICReg, CPC, BYOL/SimSiam, and JEPA from LDM, thereby providing a principled, unifying account of contrastive, non-contrastive, and stopgrad approaches.

Moreover, we revisit the role of mutual information (MI) maximization, which has been shown neither necessary nor sufficient for SSL. We show that, in situations where it appears beneficial, the underlying benefit stems from the implicit LDM effect of practical MI estimators.
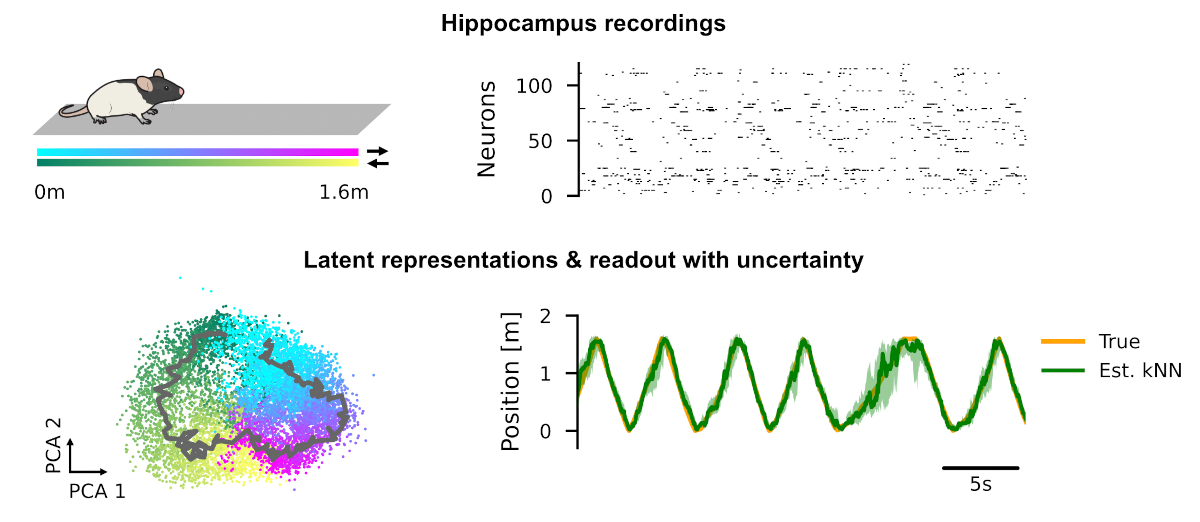
We show that the LDM perspective allows us to derive new SSL algorithms. For example, using a Kalman Filter as the predictor enables principled uncertainty quantification of learned nonlinear representations of temporal data.
Finally, LDM admits identifiability guarantees in the predictive SSL setting on temporal data. Under mild assumptions, learned representations recover the true latent variables up to affine transformations, even with nonlinear predictors.
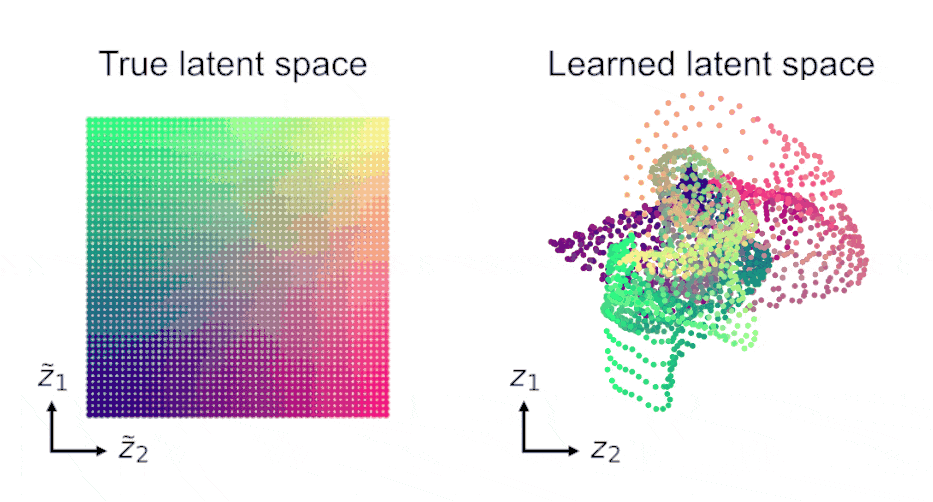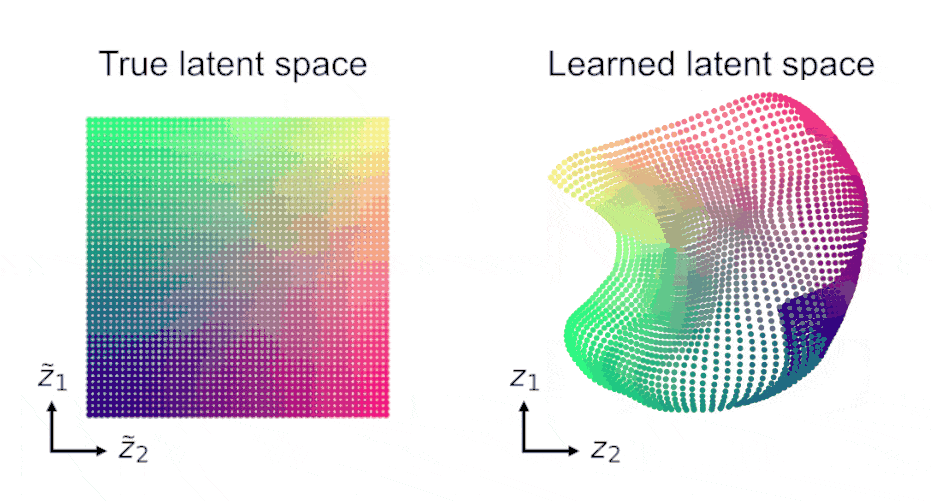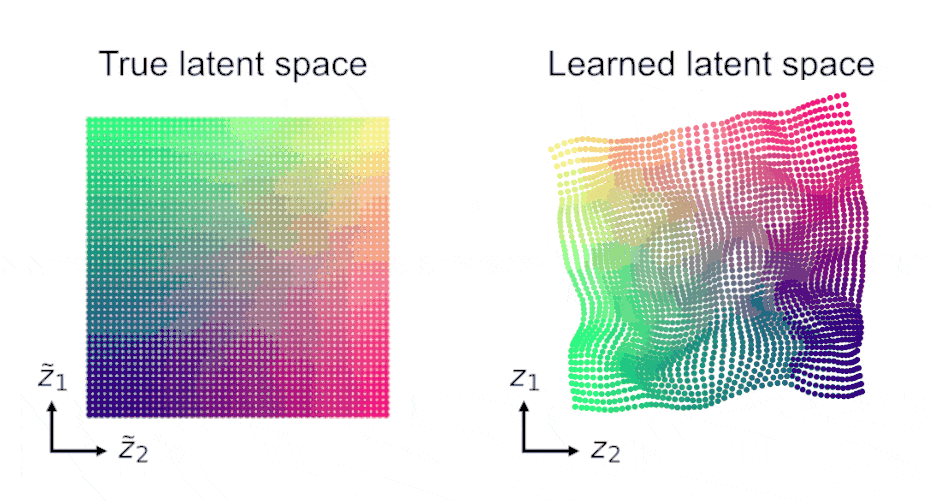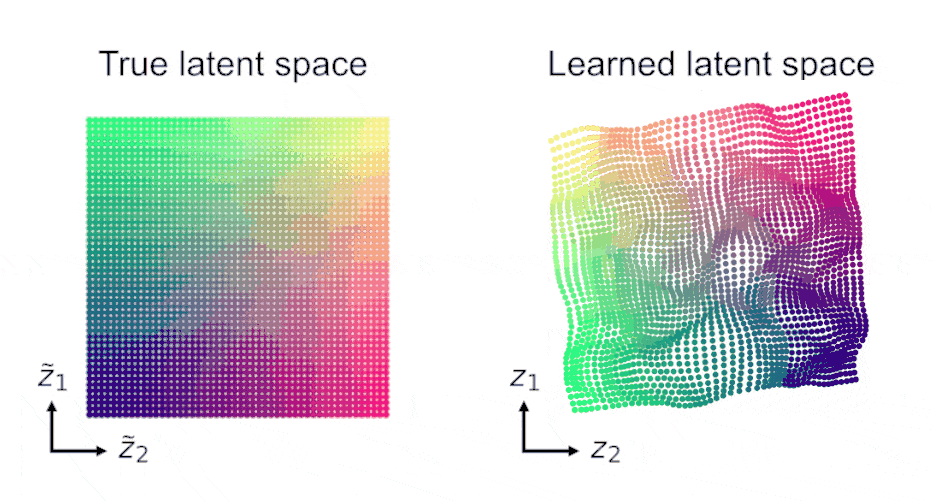
Based on these guarantees, we argue that SSL’s success is not primarily based on discarding “irrelevant” information, but instead on constraining representations directly in the latent space.