Surrogate gradients are a great tool for training spiking neural networks in computational neuroscience and neuromorphic engineering, but what is a good initialization? In our new preprint co-led by Julian and Julia, we lay out practical strategies.
Paper: https://arxiv.org/abs/2206.10226
Code: https://github.com/fmi-basel/stork
Update (2022-10-06) now published as:
Rossbroich, J., Gygax, J., and Zenke, F. (2022). Fluctuation-driven initialization for spiking neural network training. Neuromorph. Comput. Eng. 10.1088/2634-4386/ac97bb.
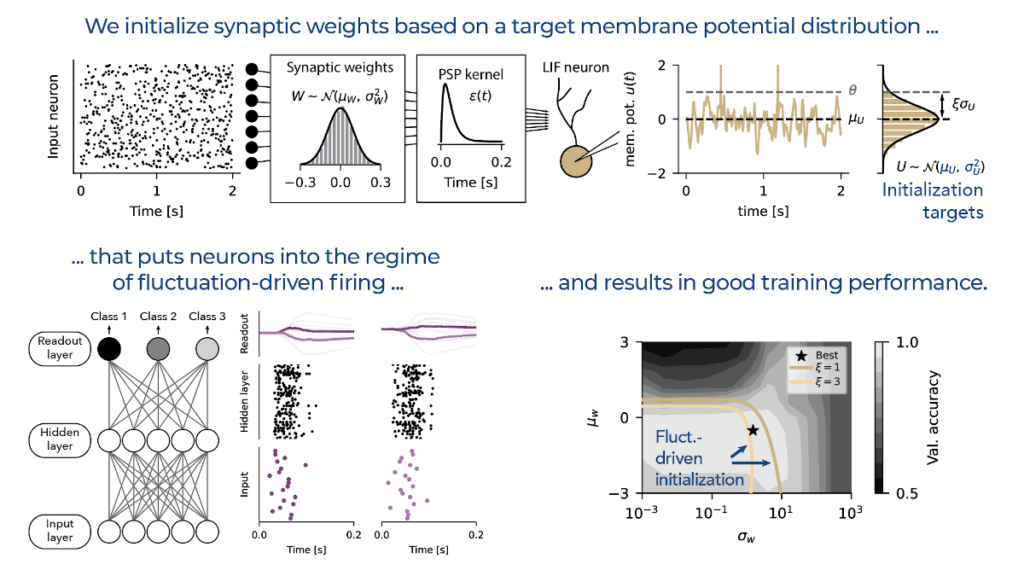
Neurons in the brain often fire seemingly stochastically due to large membrane fluctuations. We take this as our inspiration and show that initializing LIF neurons in the fluctuation-driven regime constitutes a good initial state for subsequent training.
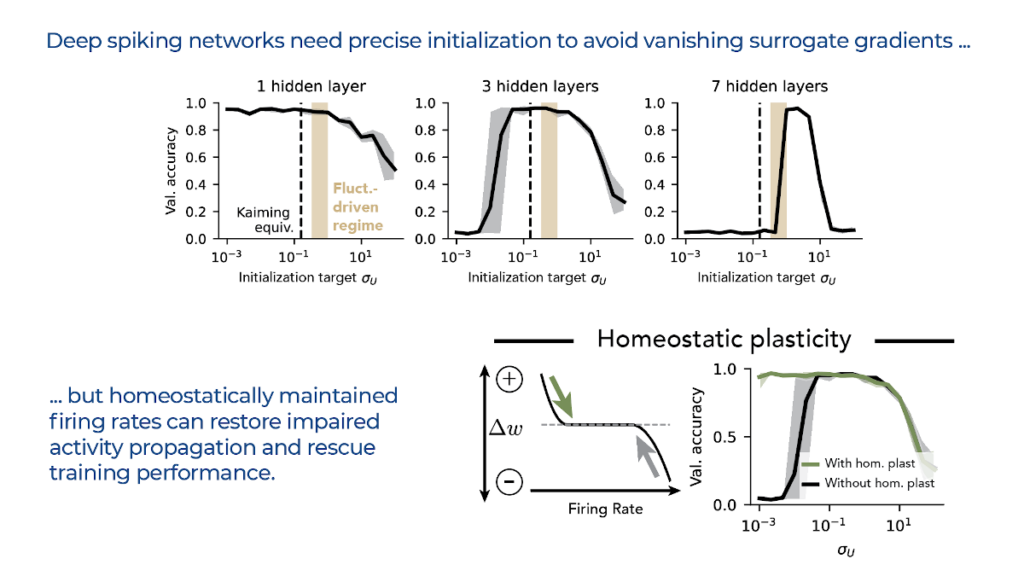
Deep spiking nets require even more care at initialization to avoid vanishing surrogate gradients. We show that firing rate homeostasis is an effective mechanism that refines the initial weights and restores activity propagation and thus training performance.
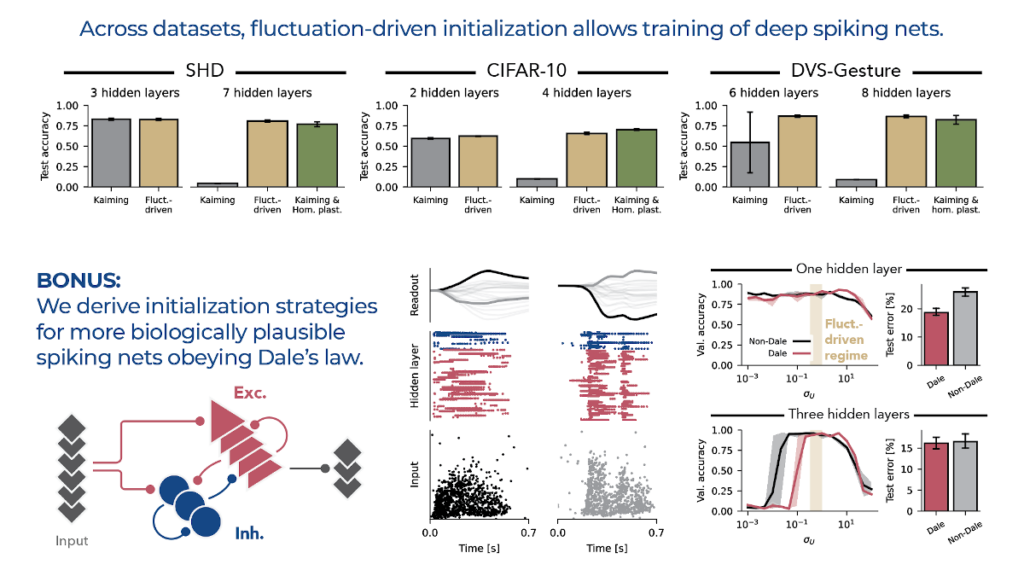
In summary, we provide practical heuristics for fluctuation-driven initialization of deep recurrent and convolutional spiking nets (including networks obeying Dale’s law) that enable training to close-to-optimal performance across datasets.