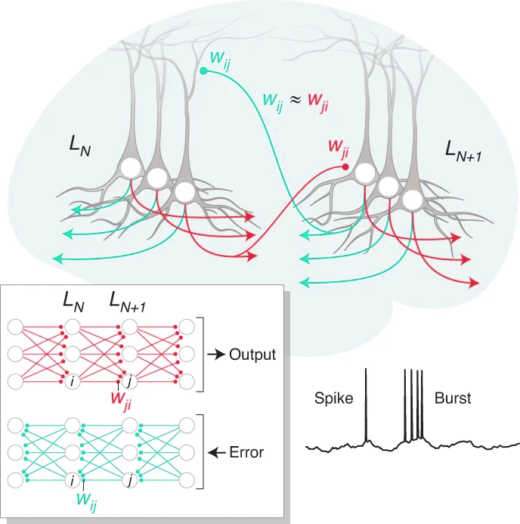
We’re excited to see this published. A new take on spatial credit assignment in cortical circuits based on Richard Naud’s idea on burst multiplexing. A truly collaborative effort lead by Alexandre Payeur and Jordan GuerguievContinue reading
Category: publications
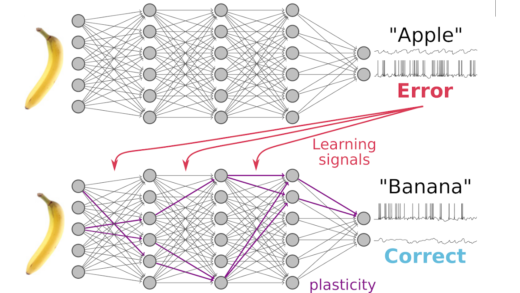
Publication: Visualizing a joint future of neuroscience and neuromorphic engineering
Happy to share this report summarizing the key contributions, discussion outcomes, and future research directions as presented at the spiking neural networks as universal function approximators meeting SNUFA2020. Paper: https://www.cell.com/neuron/fulltext/S0896-6273(21)00009-XAuthor link: https://authors.elsevier.com/a/1cbg3_KOmxI%7E6f
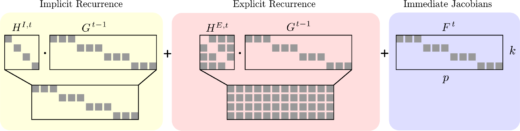
Paper: Brain-Inspired Learning on Neuromorphic Substrates
I’m happy to share our new overview paper (https://ieeexplore.ieee.org/document/9317744, preprint: arxiv.org/abs/2010.11931) on brain-inspired learning on neuromorphic substrates in (spiking) recurrent neural networks. We systematically analyze how the combination of Real-Time-Recurrent Learning (RTRL; Williams and Zipser,Continue reading
Preprint: The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks
We just put up a new preprint https://www.biorxiv.org/content/10.1101/2020.06.29.176925v1 in which we take a careful look at what makes surrogate gradients work. Spiking neural networks are notoriously hard to train using gradient-based methods due to theirContinue reading
Paper: Finding sparse trainable neural networks through Neural Tangent Transfer
New paper led by Tianlin Liu on “Finding sparse trainable neural networks through Neural Tangent Transfer” https://arxiv.org/abs/2006.08228 (and code) which was accepted at ICML. In the paper we leverage the neural tangent kernel to instantiate sparse neuralContinue reading

Paper: Surrogate gradients for analog neuromorphic computing
Update (22.01.2022): Now published as Cramer, B., Billaudelle, S., Kanya, S., Leibfried, A., Grübl, A., Karasenko, V., Pehle, C., Schreiber, K., Stradmann, Y., Weis, J., et al. (2022). Surrogate gradients for analog neuromorphic computing. PNASContinue reading
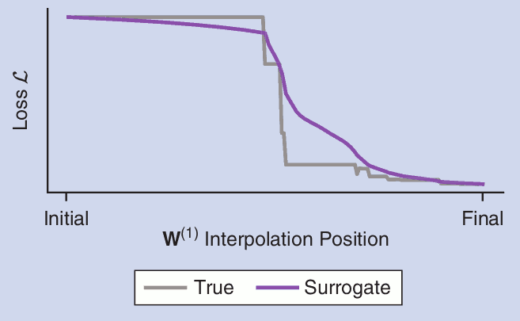
Paper: Surrogate Gradient Learning in Spiking Neural Networks
“Bringing the Power of Gradient-based optimization to spiking neural networks” We are happy to announce that our tutorial paper on Surrogate Gradient Learning in spiking neural networks now appeared in the IEEE Signal Processing Magazine.Continue reading
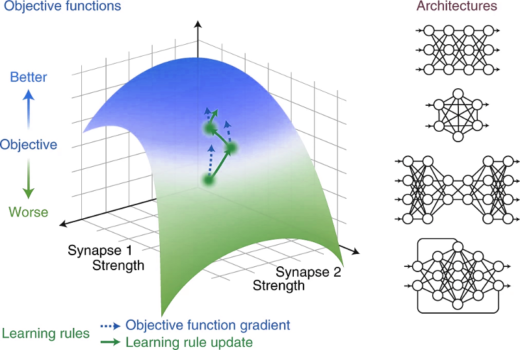
Perspective: A deep learning framework for neuroscience
Our perspective paper on how systems neuroscience can benefit from deep learning was published today. In work led by Blake Richards, Tim Lillicrap, and Konrad Kording, we argue that focusing on the three core elements usedContinue reading
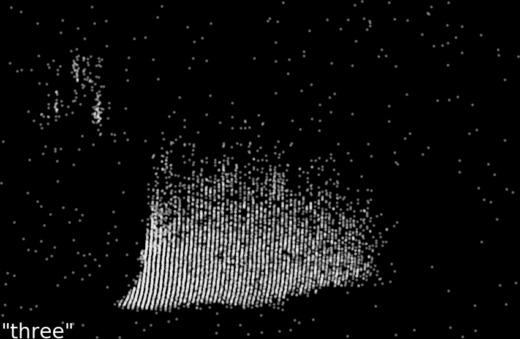
Preprint: The Heidelberg spiking datasets for the systematic evaluation of spiking neural networks
Update (2020-12-30) Now published: Cramer, B., Stradmann, Y., Schemmel, J., and Zenke, F. (2020). The Heidelberg Spiking Data Sets for the Systematic Evaluation of Spiking Neural Networks. IEEE Transactions on Neural Networks and Learning SystemsContinue reading
SuperSpike: Supervised learning in spiking neural networks — paper and code published
I am happy to announce that the SuperSpike paper and code are finally published. Here is an example of a network with one hidden layer which is learning to produce a Radcliffe Camera spike trainContinue reading