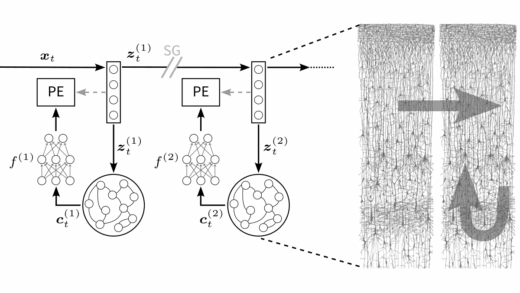
We’re happy to share our new preprint “Understanding neural circuit principles for representation learning through joint-embedding predictive architectures” led by Atena and Manu 🚀 We looked into the question how the cortex learns to representContinue reading
Category: preprint
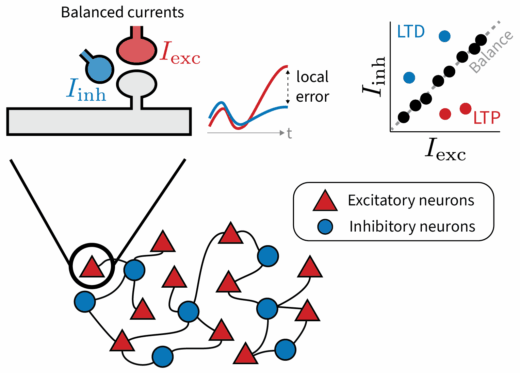
Breaking Balance: Encoding local error signals in perturbations of excitation-inhibition balance
Why does the brain maintain such precise excitatory-inhibitory balance? Our new preprint led by Julian Rossbroich explores a provocative idea: Small, targeted deviations from this balance may serve a purpose: to encode local error signalsContinue reading
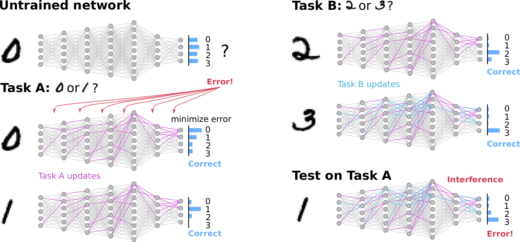
Preprint: Theories of synaptic memory consolidation and intelligent plasticity for continual learning
We are happy to present our new preprint:Zenke, F., Laborieux, A., 2024. Theories of synaptic memory consolidation and intelligent plasticity for continual learning. https://arxiv.org/abs/2405.16922 It is a book chapter in the making which covers theContinue reading
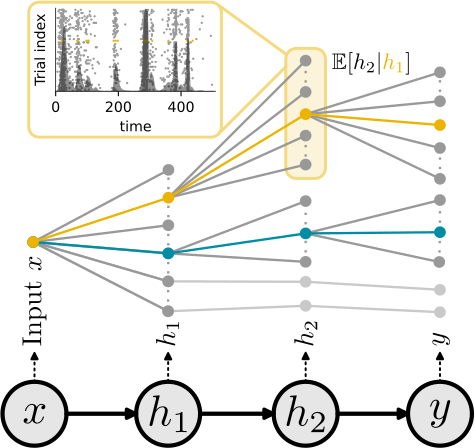
Elucidating the theoretical underpinnings of surrogate gradient learning in spiking neural networks
Surrogate gradients (SGs) are empirically successful at training spiking neural networks (SNNs). But why do they work so well, and what is their theoretical basis? In our new preprint led by Julia, we answer theseContinue reading
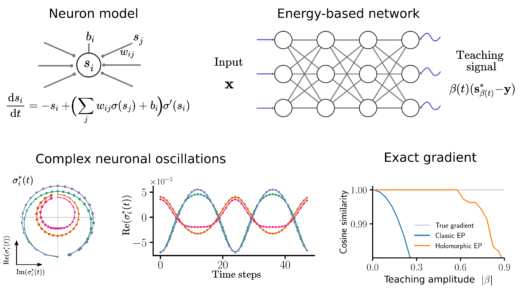
Holomorphic Equilibrium Propagation
Thrilled to introduce Holomorphic Equilibrium Propagation (hEP) in this new preprint led by Axel Laborieux. We extend classic equilibrium propagation to the complex domain and show that it computes exact gradients with finite size oscillations,Continue reading

Fluctuation-driven initialization for spiking neural network training
Surrogate gradients are a great tool for training spiking neural networks in computational neuroscience and neuromorphic engineering, but what is a good initialization? In our new preprint co-led by Julian and Julia, we lay outContinue reading
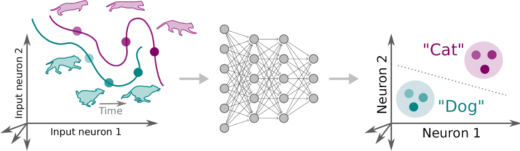
Hebbian plasticity could be the brain’s trick to make self-supervised learning work
Please take a look at our new preprint “The combination of Hebbian and predictive plasticity learns invariant object representations in deep sensory networks.” https://biorxiv.org/cgi/content/short/2022.03.17.484712v2 In this work led by Manu Srinath Halvagal we argue thatContinue reading
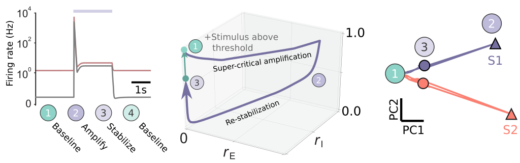
Paper: Nonlinear transient amplification in recurrent neural networks with short-term plasticity
Update (21.12.2021): Now published https://elifesciences.org/articles/71263 I am pleased to share our new preprint: “Nonlinear transient amplification in recurrent neural networks with short-term plasticity” led by Yue Kris Wu in which we study possible mechanisms forContinue reading
Preprint: The remarkable robustness of surrogate gradient learning for instilling complex function in spiking neural networks
We just put up a new preprint https://www.biorxiv.org/content/10.1101/2020.06.29.176925v1 in which we take a careful look at what makes surrogate gradients work. Spiking neural networks are notoriously hard to train using gradient-based methods due to theirContinue reading